![Popular Applications of Machine Learning in Business [2024]](https://graphite-note.com/wp-content/uploads/2022/09/Feature-Popular-Machine-Learning-Applications-For-Business-1024x576.png)
Introduction
Machine learning in business can set your business apart in so many ways. Machine learning applications in business hold a range of opportunities and value-enhancing possibilities. Graphite Note outlines some of the most popular applications of a machine learning model in business. We share an in-depth outline of machine learning in business.

Machine learning definition
Machine learning (ML) is a subfield of artificial intelligence (AI). In machine learning projects, algorithms learn from data. They then use that data to make predictions or decisions without explicit programming. By analyzing patterns in the data, the machine learning algorithm learns what features define a particular data point. The algorithm can then apply that knowledge to new data. Machine learning is:
- Data-driven: Machine learning algorithms rely upon large amounts of data to learn and improve.
- Predictive: Machine learning models are often used to make predictions about the future.
- Generalizable: Machine learning models learn from existing data. Machine learning models then apply that knowledge to new, unknown situations.
- Used for a variety of tasks: Machine learning can be used for a wide range of tasks. These include: image recognition, fraud detection, speech recognition, recommendation engines, personalization, and more.
- Uses two different approaches: unsupervised machine learning, and supervised machine learning. Supervised machine learning and supervised learning algorithms require labeled data. Unsupervised machine learning deals with unlabelled data. This is where the data points lack predefined labels or categories. In unsupervised machine learning, the machine learning model is left to its own devices. The unsupervised machine learning and unsupervised learning models must discover hidden patterns and structures within the data on its own. Unsupervised learning algorithms are often used for tasks like clustering and dimensionality reduction. While an unsupervised learning technique doesn’t use labeled data, it can be difficult to interpret the results. This also means it’s difficult to assess if the model is on the right track. Unsupervised learning algorithms have a variety of use cases, but we’ll discuss those another time.
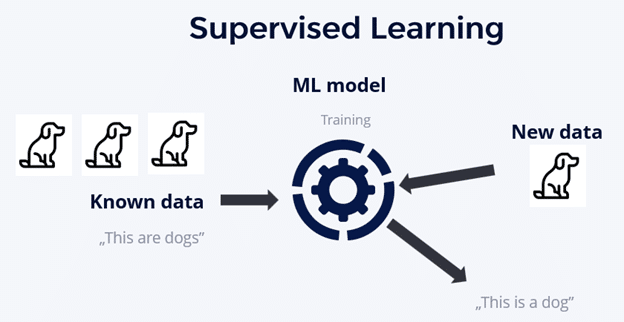
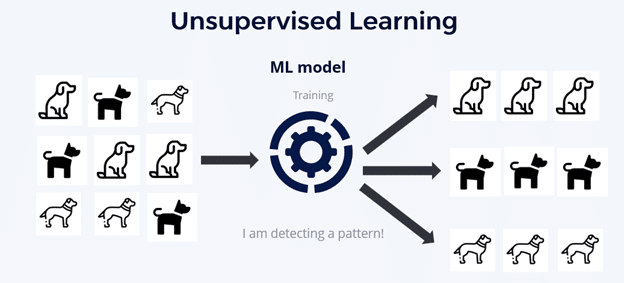
Uses different types of data: training data, validation data, and test data. Training data is used to train a machine learning model to predict an expected outcome. Validation data is used to check the accuracy and quality of the model used on the training data. Test data is used to perform a realistic check on an algorithm. Test data, also known as a testing set, or test set, confirms if the machine learning model is accurate.
Machine learning statistics
As the applications for machine learning in business grow, here are a few things you should know:
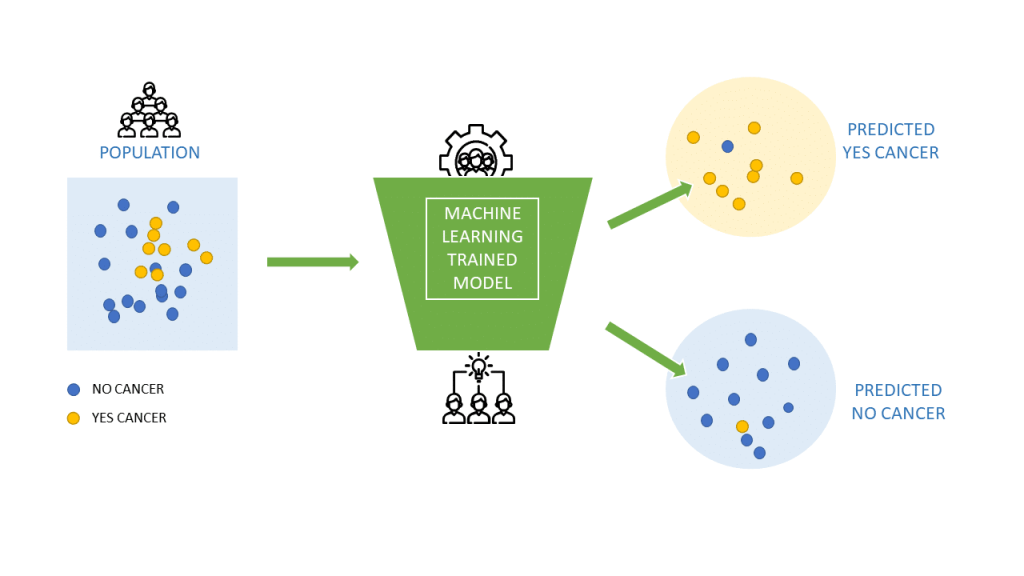
- A recent McKinsey survey outlined that 56% of organizations are using machine learning in at least one business function, to optimize a business function.
- The AI market will grow in value to USD 407.0 billion by 2027 – at a fantastic Compound Annual Growth Rate (CAGR) of 36.2%. Business analytics is a fast growing industry.
Only 29% of small and medium enterprises (SMEs) said they had adopted AI technology, in a recent article by Forbes. Machine learning applications for small business are growing exponentially, and present a number of important opportunities. Machine learning can help you use business analytics to optimize business operations. AI applications can help you optimize business processes. As a business owner, you can improve your business decisions and business efficiency using data science.
Applications of machine learning in business
Machine learning and data science provides businesses with an abundance of opportunities to optimize their operations and grow their profitability. There are many different types of learning use that can bolster your business, with a useful ml algorithm, and big data. Here are some popular applications and use cases of machine learning and ml algorithms in business.
Predict lead conversion with machine learning
Sales and marketing teams find it challenging to predict their conversion rates, especially when they have multiple lead pipelines that generate different sales levels. Generating leads is the lifeblood of your business. You can predict lead conversion with machine learning and enhance your sales process. Your ability to prioritize and follow up on the right leads can significantly affect your bottom line. Manually lead scoring or categorizing lead attributes and activities can be a tremendously tedious task. Sales can fluctuate wildly depending on the time of year, too.
Some businesses also face significant shifts in demand throughout the year based on weather, seasonal events, industry trends, and more. These fluctuations affect what products or services people want and their willingness to pay for them. Predictive analytics can help you to predict lead conversion. This can improve your customer experience, and you can use predictive analytics to forecast product demand. You can analyze customer satisfaction, customer service levels, with confidence. This is just one use case of machine learning.
Predict revenue with machine learning
Revenue forecasting is crucial for a robust, effective business plan that will lead to long-term success. Revenue forecasting helps business owners develop and streamline strategies for growth and answers questions like how much they intend to grow and how much capital is needed for a healthy cash flow. Estimating revenue over a given period is crucial for correctly pricing products and services. A sophisticated pricing strategy and cash flow can help the business thrive regardless of demand fluctuations, emerging trends, and product seasonality. However, accurate revenue forecasting can be difficult to achieve. There are many challenges, such as finding and collecting the best data and choosing the proper forecasting methods to suit the business. With actionable insights, you can predict revenue and optimize your business’ cash flow.
Forecast product demand with machine learning
Knowing how much demand a business will generate within a certain period is essential. It helps companies evaluate how much they should spend on production, allocation of resources, and even marketing. Demand forecasting enables businesses to estimate and predict customer demand for a particular product or service. An accurate forecast can significantly reduce risk and help sales and product teams make intelligent decisions that will have an impact on revenue and profit margins.
However, arriving at an accurate demand forecast can be difficult. Approximating demand can bleed a company’s resources, increase losses, and disappoint customers. Poor demand forecasting also results in a significant loss in market share to competitors or even a company’s loyal market base if they cannot satisfy customer demand. Machine learning can optimize your supply chain management, discover if a new product is worthwhile, or if certain tasks can be eliminated.
Predict customer churn with machine learning
The one challenge businesses always face is customer churn. A churn is when customers stop buying a product or opt-out of service. Often, this entails the need to find new leads and pipelines so you can still meet revenue targets. The ideal solution, however, is to map out reasons for customer churn to prevent customers from turning to a competitor. Understanding customer churn goes together with customer retention analysis. Knowing why customers are leaving can improve your customer retention rates and help you understand the weaknesses of your product and strategy.
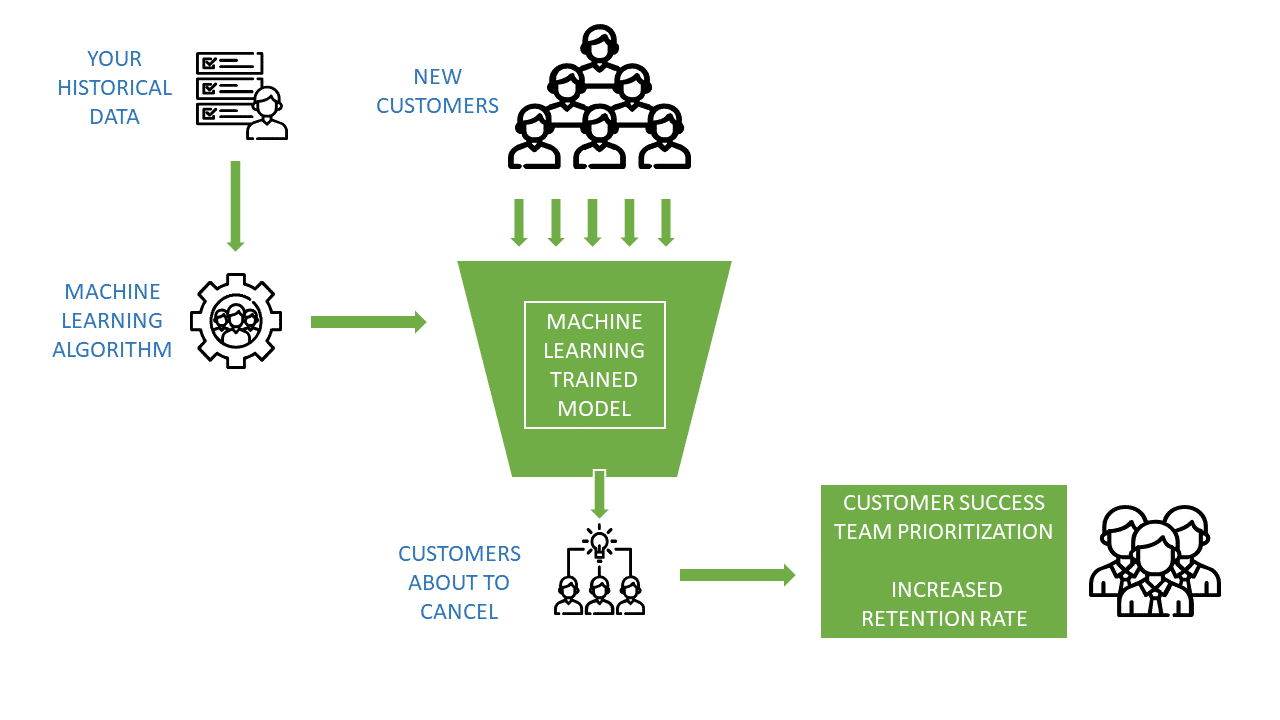
Monitoring churn helps businesses stay in touch with their customer base. Though it might seem straightforward, many companies find it challenging to address churn. Churn can be challenging to predict as the raw data needed for an accurate analysis can be messy and might require data to be engineered into a more usable format. Collecting large datasets can be labor-intensive, requires removing outliers, and identifying potentially essential features. Large datasets can, however, reveal key trends for you to improve your customer retention strategies.
Predict cross-selling with machine learning
For long-term growth and success, businesses must generate consistent revenues and high-profit margins. Cross-selling is one way to do this, especially if the company has several complementary products or services. However, cross-selling has its challenges, even if customer demand is high. Marketing and sales teams may not have the knowledge to sell many different products to various customer segments. They may be unable to address the correct type of customer poised to purchase a specific product or service. Furthermore, some customers may not engage with cross-selling strategies, especially if they are not interested in the offered bundles. Ml solutions can help you design cross-selling strategies.
ABC product analysis with machine learning
Companies must have robust inventory management systems to track and monitor every movement of their items throughout the logistics process. Crucial data such as product descriptions and the stock numbers for each product type must be readily available and up-to-date. Certain products generate more revenue than others. It comes down to customer demand, production costs, and risk calculations.
Businesses must identify which of their products or services can impact their total sales to make improvements and plan for growth. ABC product analysis helps companies manage their inventory and highlight essential products. However, proper research requires extensive data collection: inventory data, product value, percentage value, and the total value of the inventory. Using ML solutions could help you undertake ABC product analysis.
Customer segmentation and product segmentation with machine learning
Customer or product segmentation helps companies laser focus their marketing strategies on their target audience. Businesses can allocate their marketing and sales budgets in the most efficient and productive ways because they can target the right audience segment with a specific product they will likely purchase. Good segmentation gives companies a deeper understanding of their markets. And once they understand their audience, they will gain an edge over the competition.
However, effective segmentation largely depends on data quality and sources. To properly assess customer and product segmentation, specific parameters are required regarding demographics, psychographics, and behavioral and geographical data. This data can be collected through surveys, transaction histories, and customer information. Relying solely on past historical behavior with only limited data sets will result in inaccurate segmentation that will not benefit the business.
Predict deal size with machine learning
Businesses want to close the most significant possible deals to boost their revenue stream significantly. Tracking and cultivating such leads requires time and resources. Often, companies take complicated steps to find new pipelines and leads, and there is no direct effort to predict the value of a single lead. If businesses direct some of their resources into assessing what each client could bring and the deal they can close, growth can seem more effortless than ever.
Furthermore, one big deal can be enough to upend an existing sales forecast and affect a business’s bottom line. It can be difficult for companies to determine which leads can be converted into big sales and which are worthy of the sales and marketing team’s attention. You can make more informed decisions using machine learning. There is immense potential for your business, using machine learning.
Customer retention analysis with machine learning
One of the biggest challenges for any business is retaining existing customers. Understanding why customers stop supporting businesses and what triggers churn is essential. Customer retention is a crucial factor in gaining revenue without increasing costs. Customer retention analysis and sentiment analysis uses data, including customer sentiment data, to identify behaviors that affect churn and strategies that need improvement.
Direct customer feedback and surveys help companies understand why and how customers lose interest in a service or product. However, analyzing churn and customer sentiment can be challenging. For example, sentiment analysis requires accurate data to predict customer behavior. Transaction history, customer information, and other metrics must be collected and analyzed efficiently. Large amounts of raw data for churn are often incredibly complex and require much work to be beneficial.
Conclusion
Machine learning is just one of the few ways in which machines learn. The parent field of artificial intelligence has yet to be fully explored, and there is tremendous potential for further advancements when applied to many industries. Today SMEs can use no-code machine learning platforms like Graphite Note to fill the gap if they don’t have in-house AI talent. No-code machine learning and using an effective ML model is a suitable option for non-technical people because it is less intimidating.

This new technology allows everyday business users to create fantastic machine-learning applications without writing a single line of code. Machine learning can help make manual and traditional processes much more efficient while reducing the cost required to put them into practice. Used to its best potential, machine learning holds the power to provide more insight where humans couldn’t. Understanding machine learning processes and applications is crucial in shaping their application for your business or personal use.

Transform your business with Graphite Note’s prebuilt machine learning models that work with any dataset, regardless of industry. Our data-agnostic platform delivers insights and predictions in minutes, giving you a competitive edge. Explore high-impact use cases that drive real business outcomes:
Key Use Cases:
1. Lead Scoring: Prioritize high-quality leads and increase conversion rates. Customer Churn Prevention: Retain more customers by identifying those at risk of churning.
2. Cross-Sell Optimization: Boost sales by targeting customers likely to purchase additional products.
3. Time Series Forecasting: Optimize inventory and plan for sales peaks and low periods.
4. Customer & Product Segmentation: Segment customers for personalized strategies and sales growth.
5. Customer Lifetime Value: Predict customer value over time to maximize revenue.
6. Predictive Maintenance: Reduce downtime, cut costs, and extend machinery life. Start leveraging Graphite Note today for smarter decisions and faster results!
Try it for free and see how predictive and prescriptive analytics can revolutionize your strategy.


