
Understanding data labeling for machine learning is critical. Accurate data labeling enables you to create effective machine learning models. Automated data labeling, a data labeling tool, or manual data labeling, acts as the teacher. Data labeling guides algorithms towards accurate predictions. In the giant world of big data, data labeling is the key towards machine learning success. Collecting and labeling data helps you build better machine learning models. Machine learning models empower you to use no-code analytics to inform decision making.

Data label definition
Data labeling is the process of adding descriptive tags or categories to raw data. Data labeling and data labeling tools transform data into a digestible format for learning algorithms. Data labeling and data labeling tools may involve:
- Identifying objects in images: Marking cars, pedestrians, and traffic signs in autonomous vehicles’ training dataset.
- Classifying sentiments in text: Labeling reviews as positive, negative, or neutral for sentiment analysis tools.
- Annotating audio recordings: Identifying spoken words or background noises for speech recognition software.
The importance of data labeling for machine learning
Data labeling for machine learning is critical. Data labeling is the foundation for accuracy. Data labeling for machine learning also enables efficiency and cost-effectiveness. This is why automated data labeling and data labeling tools have become popular in machine learning. High-quality data labeling enables faster learning, lower data needs, and reduced training time for a machine learning model. In turn, high quality data labeling for machine learning applications leads to:
- Reduced development costs: Less data collection, annotation, and computational power needed for your machine learning algorithms to work.
- Faster time to market: You can get your artificial intelligence-powered solutions to users quicker. Effective data labeling techniques can help you get your product to customers sooner.
- Improved model performance: Accurate data labels lead to more robust and reliable predictions. Labeling your data points and specific data leads to improved model performance.
72% of businesses report an increase in revenue after implementing no-code predictive analytics. By 2025, the no-code market is set to be valued at $15 billion. While you may think you need a team of data scientists to harness machine learning, no-code predictive analytics can help you build an AI model to empower your decision making.
How to implement high quality data labeling for machine learning
Data is the key ingredient to any successful machine learning process. Data needs to be correctly labeled for your machine learning model to yield the best results, and be able to correctly identify new data. Without data labels, any data set could look like a jumble of numbers, words, and characters to machines. This makes it impossible to understand what each piece of data means. It will also mean your model cannot make an accurate predicition. Data labeling is critical for supervised machine learning, also known as supervised learning. Unsupervised machine learning uses unlabeled data. We outline some of the best practices for common types of data labeling.
How to conduct data labeling for machine learning
Data labeling can take on many forms, like audio labeling, entity name recognition, image classification, image annotation, data annotation, or various ways to label input data. How you label your data will determine your data quality. Your data quality, in turn, will affect how your ML model performs. AI models and machine learning models rely on good input data, and well labeled data, to enhance their results. Isolating key points about your raw data and input data is important for your machine learning model. There are different ways to undertake a data labeling process and data labeling approaches for your machine learning projects:
- Using human intelligence: Humans can provide context and understanding to data sets. Humans are, however, limited, in their ability to manage labeling tasks. Humans are only able to provide labels for data when there is a given context or understanding. Humans are most often used when the data has many classes that lack identifiers or labels. You could use data labeling teams, human annotators, or data labelers, to conduct this form of data labeling.
- Data labeling services: A data labeling platform supplements knowledge or context-based labels. A data labeling service is often provided by third-party data labeling companies or through automated techniques. Automated data labeling, or a data labeling tool, is often used for large amounts of data, but are less complex.
Data labeling for predictive lead scoring
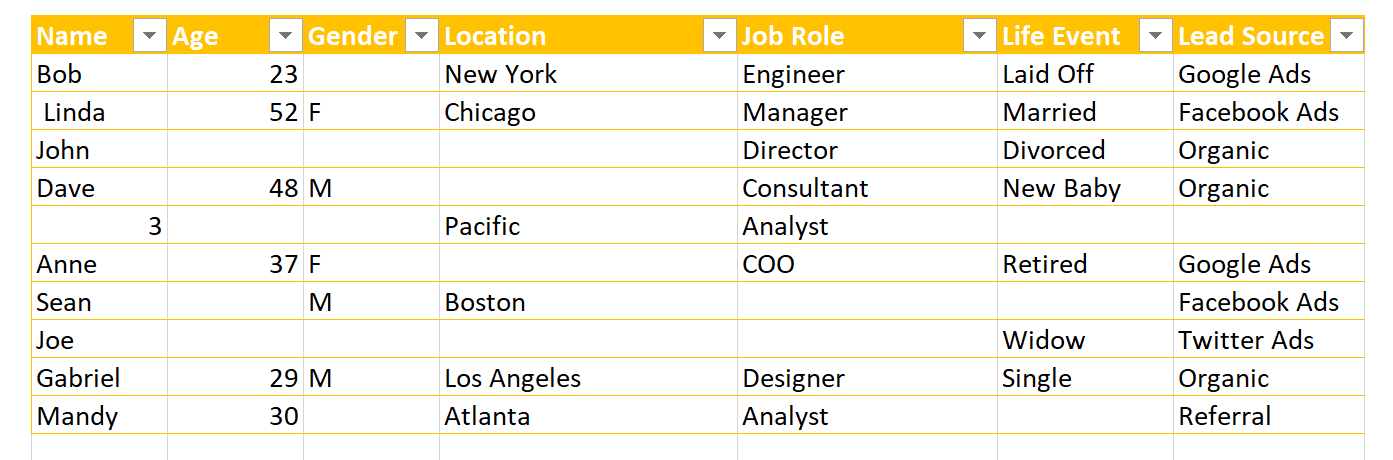
Predictive lead scoring empowers you to predict which leads are most likely to convert into sales. Your machine learning model needs the right information to give the correct results and accurate predictions. That’s where data labeling for machine learning comes in. For example, you’re a salesperson who is trying to predict which leads will convert. Your boss gives you a list of leads to work with, but it could be in better condition. Some leads are missing information, and the “converted” column is inconsistent. Some say “yes,” some say “no,” and some say nothing at all. You could make an estimation, but that’s not an assured result. If you had a team of data label specialists cleaning up the list, they would fill in missing information. Your data label specialists would then ensure the converted column is consistent. Thereafter, your list would provide clear insights into your leads and conversions. High quality data labeling enables your predictive lead scoring model to make an accurate prediction. Data labeling for machine learning readies your model for predictive analytics.
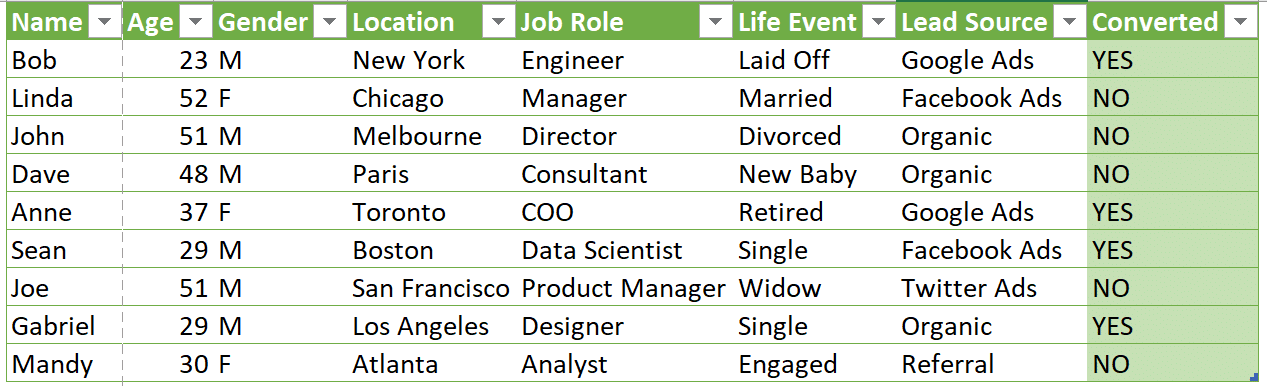
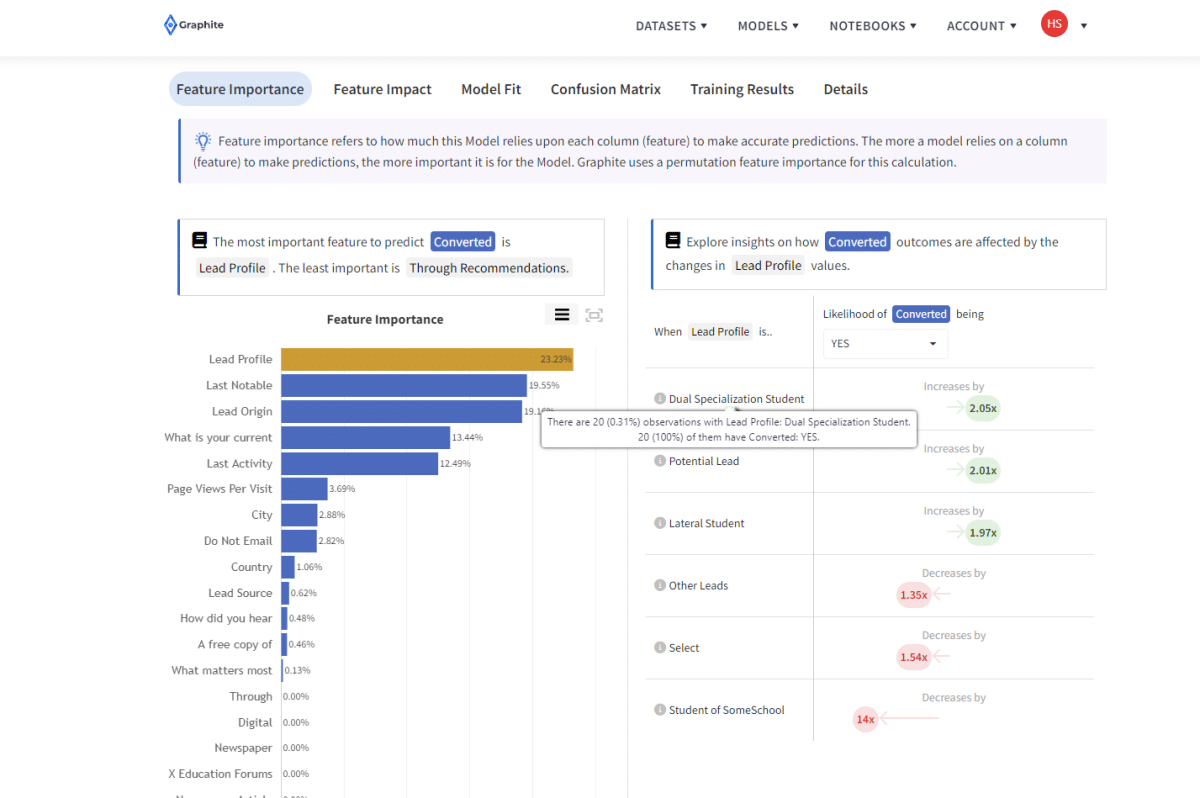

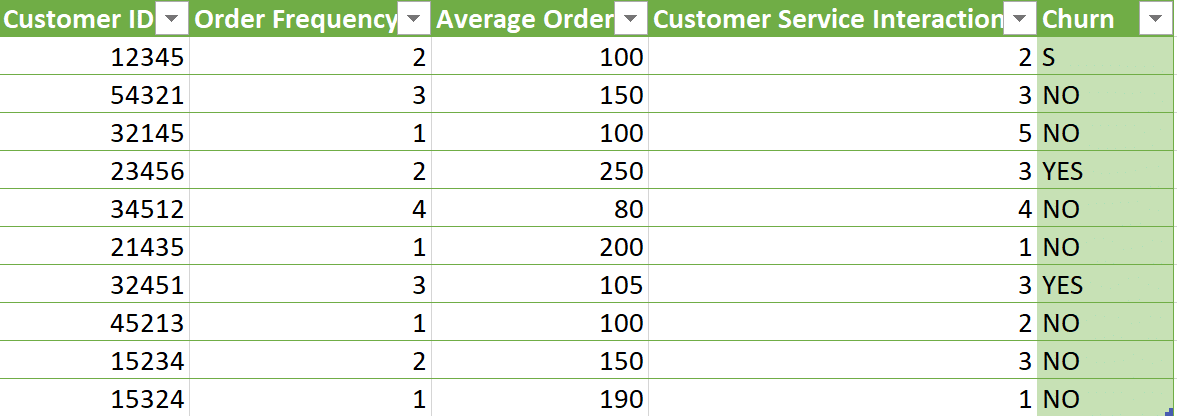
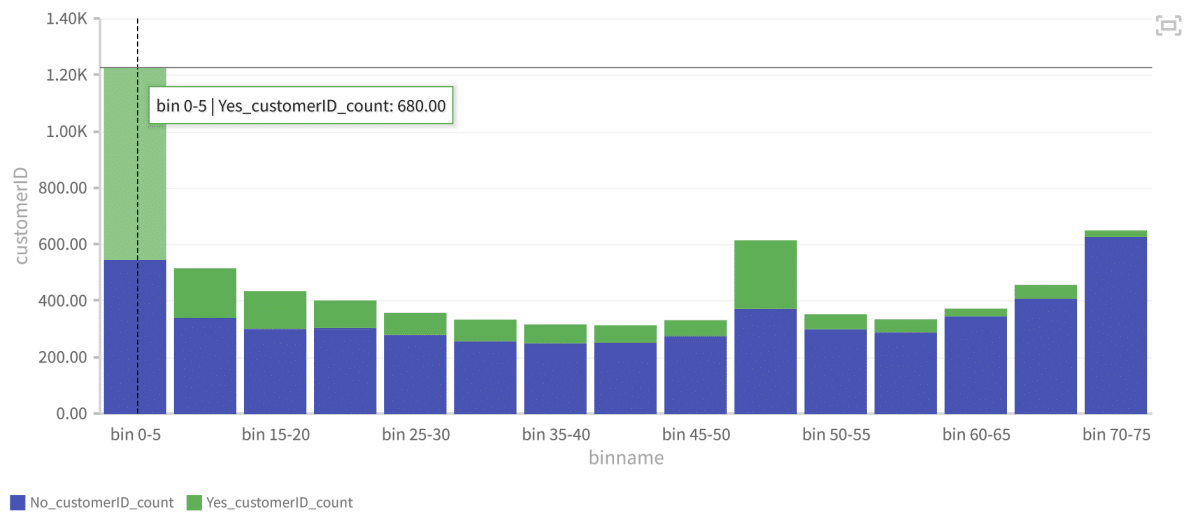
Data labeling for predictive customer churn
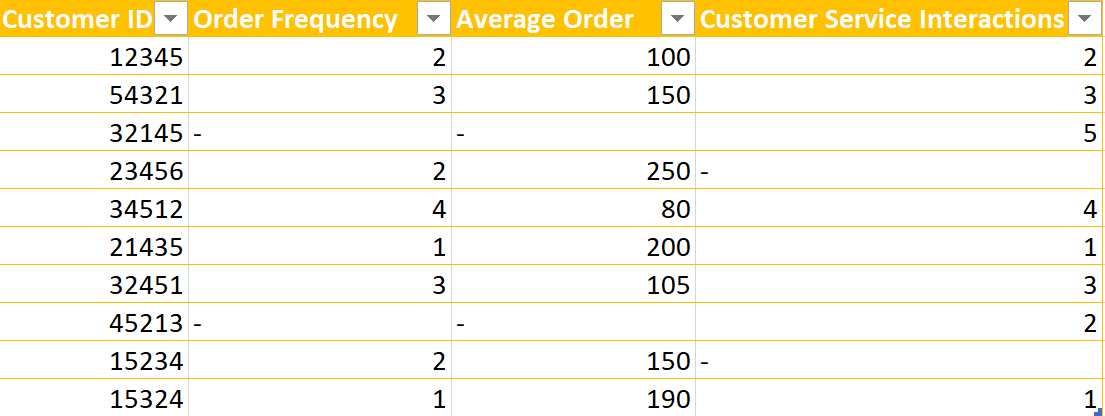
Predictive customer churn is a valuable metric to understand for your business. Customer churn refers to the rate at which your customers stop participating in your sales or operational funnels. Customer churn can also relate to their exit points within a system or process. Customer churn occurs when your customer stops interacting with your businesss. This creates a “leak” whereby customers leave your business. This leak signifies lost revenue and missed opportunities. Predictive customer churn models help you augment your operations and improve your customer experience. In turn, this leads to improved customer retention and business growth. Data labeling for machine learning helps you create effective machine learning models to predict customer churn. High quality data labeling for machine learning helps you overcome gaps in your customer data. This leads to better results in predicting customer churn. Inconsistent data sets, or incomplete data sets, can affect the reliability of your model’s results. Using accurate data labeling and data tagging helps you fill in the gaps and provide a consistent target column. This means that, thanks to the way you label data, your machine model can accurately predict customer churn. Once all customer information is complete and consistent, the target column indicates whether a customer has churned. With a clear target column, your training data set and validation data set are now ready for predictive analytics. You can use it to identify customer behavior patterns and trends. Then, you can make informed decisions about retaining your best customers.
Data labeling for predictive credit scoring
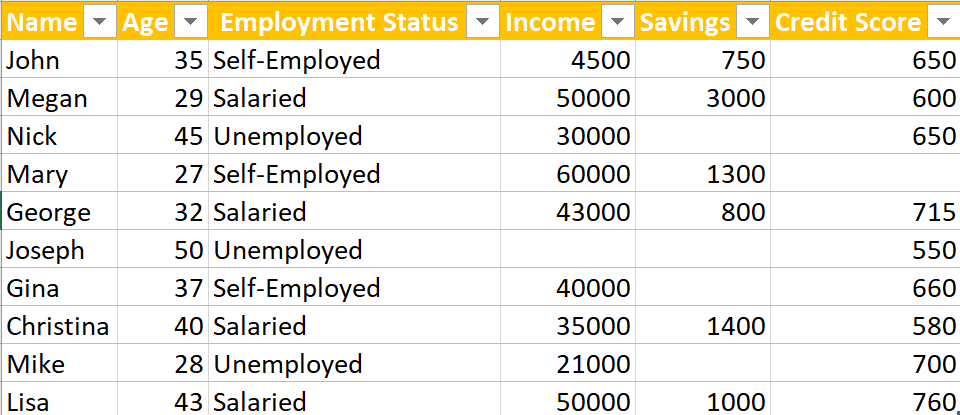
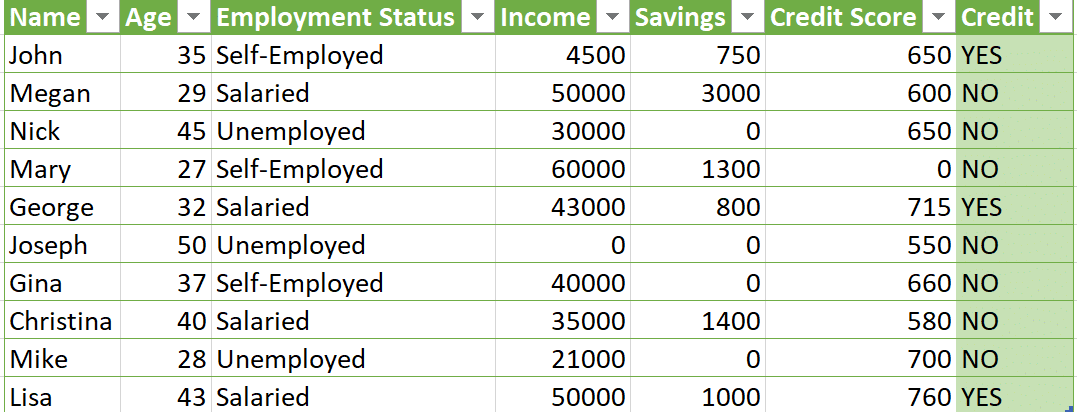
Predictive credit scoring predicts which customers will most likely take out a loan or credit. Using accurate data labeling for machine learning helps you better identify those customers. Data labeling for machine learning enables you to build effective machine learning models for predictive credit scoring. This, in turn, helps you identify customers who can apply for credit with you. Data labeling for machine learning can also help you identify customers who are likely to apply for credit with you. Ensuring you maintain good quality control measures over your data labeling helps you overcome gaps in your customer data. This leads to better results in predicting credit scoring, as a result of your quality assurance process. Inconsistent or incomplete datasets, or massive amounts of data, can affect the reliability of your machine learning model’s results. Using accurate data labeling for machine learning helps you fill in the gaps and provide a consistent target column. Thanks to data labeling, your machine model can predict credit scoring with greater accuracy. Once all customer information is complete and consistent, the target column indicates whether a customer can apply for credit with you, or if they are likely to. With a clear target column, your dataset is now ready for predictive analytics. You can use it to identify customers to target your products towards.
Data labeling for machine learning is essential for success. Accurate data labeling for machine learning is like knowing which ingredients to use in a recipe. Data labeling for machine learning enables you to make better business decisions. Data labeling for machine learning also helps you make more accurate customer predictions. High quality data labeling creates high quality datasets, which leads to more accurate results. Remember: you don’t need to be an expert in data science to use machine learning. You have subject matter expertise or domain expertise in your business, and no-code predictive analytics can help you make more informed choices about your operations.

Transform your business with Graphite Note’s prebuilt machine learning models that work with any dataset, regardless of industry. Our data-agnostic platform delivers insights and predictions in minutes, giving you a competitive edge. Explore high-impact use cases that drive real business outcomes:
Key Use Cases:
1. Lead Scoring: Prioritize high-quality leads and increase conversion rates. Customer Churn Prevention: Retain more customers by identifying those at risk of churning.
2. Cross-Sell Optimization: Boost sales by targeting customers likely to purchase additional products.
3. Time Series Forecasting: Optimize inventory and plan for sales peaks and low periods.
4. Customer & Product Segmentation: Segment customers for personalized strategies and sales growth.
5. Customer Lifetime Value: Predict customer value over time to maximize revenue.
6. Predictive Maintenance: Reduce downtime, cut costs, and extend machinery life. Start leveraging Graphite Note today for smarter decisions and faster results!
Try it for free and see how predictive and prescriptive analytics can revolutionize your strategy.


