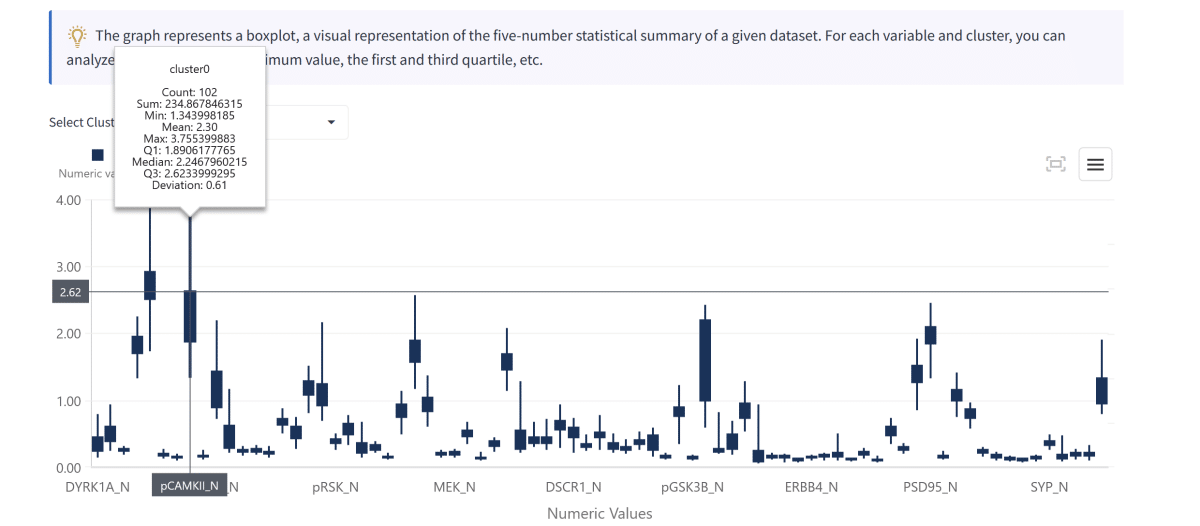
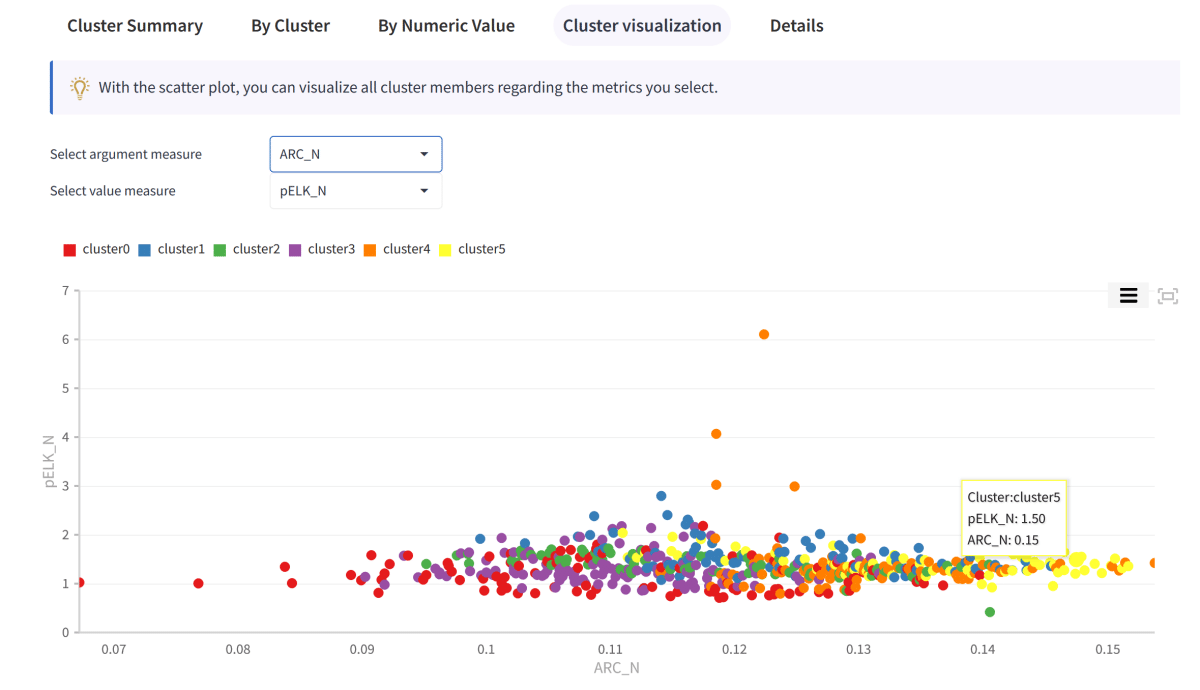
What is Unsupervised Machine Learning?
An unsupervised machine learning technique uses a machine learning algorithm. The algorithm learns using its own plain, unlabeled data. Unsupervised machine learning algorithms can reveal interesting insights in the process.
Unsupervised machine learning algorithms don’t need any human intervention. That means you won’t need to sit down and assist in its processes. In comparison to supervised machine learning techniques, this is excellent. Supervised machine learning techniques need some level of human intervention. How does an unsupervised learning algorithm benefit you or improve your decisions?

Machine Learning Unsupervised – What Is It?
Unsupervised machine learning is also known as unsupervised learning. It is also called an unsupervised learning method. Unsupervised learning algortihms use machine learning to categorize and analyze unlabeled data. An unsupervised learning method is often used in exploratory data analysis. Unsupervised learning algorithms have a wide range of applications.
Unlike supervised machine learning or supervised machine learning models, you work without clear values. It can’t used for machine learning approaches that need specific data values or labeled datasets.Unsupervised learning techniques are quite helpful in helping you discover the structure of your data. This makes it useful across a wide range of other data science applications. These include customer analytics to understanding whale language.
Unsupervised Machine Learning Vs Supervised Machine Learning
The key difference between supervised and unsupervised machine learning lies in the data used for training. Supervised learning models are trained on labeled data, where each data point has a corresponding label or desired output. This allows the model to learn the relationship between the input and output and make predictions for new data. Unsupervised learning, on the other hand, deals with unlabeled data. Unsupervised machine learning algorithms identify hidden patterns and structures within the data itself. These can include groupings or relationships between data points.
How Do Machines Learn In This Setup?
An unsupervised machine learning model uses input data only to learn. It then applies specific algorithms to automatically analyze the data sets. After that, the data is segmented into groups. Its main goal is to figure out relationships within the dataset it’s fed. As such, it’s more frequently used to gather results when you don’t necessarily know what to expect. Unsupervised learning uses input data to find the value of output data.
The Importance Of Unsupervised Machine Learning
Unsupervised machine learning is more commonly used to help you understand your existing customer base on a deeper level. There is no way to measure the accuracy of its results. Unsupervised machine learning shouldn’t be used to analyze data where you have an expected output. Unsupervised machine learning is a powerful data analysis tool that can help you find unknown patterns. Because of this, it’s also often used in cybersecurity to help determine hacking patterns.
Common Approaches In Unsupervised Machine Learning
Unsupervised learning models are often used to accomplish three main tasks. Depending on your needs, it’s important to know which approach might work for you. Take a look at these approaches below.
Clustering
The most common approach, clustering groups input-only data based on similarities and differences. This is helpful for finding specific patterns in the information you provide the model with – such as customer activity.
There are currently four sub-approaches when it comes to clustering.
- Exclusive clustering asserts that data points can only appear in one group. This is often used in market, image, and document segmentation.
- Unlike the former, overlapping clusters allows data points to belong in multiple clusters.
- Hierarchical clustering is also known as HCA. HCA categorizes data sets based on their similarities following a hierarchical structure. HCA is often used to organize social network data. HCA is similar to the way files on your computer are segmented into folders.
Probabilistic clustering is used to solve soft clustering problems. Probabilistic clustering groups data points according to how likely they are to belong to something. One of its most common examples is the Gaussian Mixture Model.
Association Rules
This method follows a specific set of rules to determine relationships between data points. It’s used in market basket analytics. This is where businesses analyze customer activity based on specific patterns. These are often applied in cross-selling, upselling, or recommendation engines.
Dimensionality Reduction
This approach is used to prevent overfitting. It is used when your data set has a high value density. Dimensionality reduction minimizes the data inputs into smaller, bite-sized pieces. What’s even more impressive is that it does so without harming the integrity of your data.
There are several dimensionality reduction methods used to preprocess data such as:
- Principal component analysis or PCA.
- Singular value decomposition or SVD.
- Autoencoders.
What Can Machine Learning Unsupervised Be Used For?
Unsupervised learning is mainly used to help improve user or customer experience. It also has applications in cybersecurity, social networking, and quality assurance for systems.
In its purest sense, UML can give you a glimpse of large data sets to help you cultivate a result. Take a look at its most common applications below:
E-commerce
Marketplaces and webstores often apply “customer who bought this also bought” techniques. This drives interest in certain products and helps upsell customers. It does this in a way that looks like you’re providing added value to their experience
News
Google News is one of the best examples when it comes to unsupervised learning. The platform categorizes its articles into sections labeled under specific themes. This makes it easier for their readers to find relevant information.
Computer Vision
Object recognition is one of the most common examples of applied unsupervised machine learning. These perception tasks help computers index information for recognizing objects.
Detecting Anomalies
While unsupervised learning can be used to find similarities in a data set, it’s also efficient in finding new activity. It is commonly applied in cybersecurity. Anomalies alert the analyst when there is a potential threat in security.

Conclusion
Unsupervised machine learning may not be able to provide you with specific values, but it’s highly effective when it comes to giving you answers.Platforms like Graphite Note employ the use of unsupervised machine learning to help.


