
Labeled vs Unlabeled Data
Introduction
Labeled vs unlabeled data is an important concept to understand in the world of Artificial Intelligence (AI). Artificial intelligence (AI) is now a vital part of every business. You may have read many news articles about the rise of ML and AI. It’s not news articles, though: AI and ML help businesses like yours to optimize their operations and improve their decision making. The use of machine learning (ML) helps you reduce process-driven losses, increase sales, and lower expenses. In this article, we explain how the right dataset (labeled vs unlabeled data) for a machine learning project can help you use predictive analysis. Data labeling is an important part of creating your machine learning model.
Brief overview of the importance of data in machine learning
ML automates data analysis through analytical model building. ML is a branch of AI that uses systems to analyze data. ML identifies patterns in the data, and makes decisions with little intervention from humans. ML enables software applications to be more accurate. Machine learning algorithms use various types of data to predict new values. Data is the backbone of any ML project. The quality and quantity of data available plays a crucial role in the success of any machine learning model. One of the most important aspects of data preparation is data labeling, which is the process of assigning meaningful labels to the data. Labeling data helps you make more accurate predictions. Remember: you’ll be using your training dataset, validation dataset, and testing dataset. Machine learning uses a combination of training data, validation data, and test data points.
Labeled data
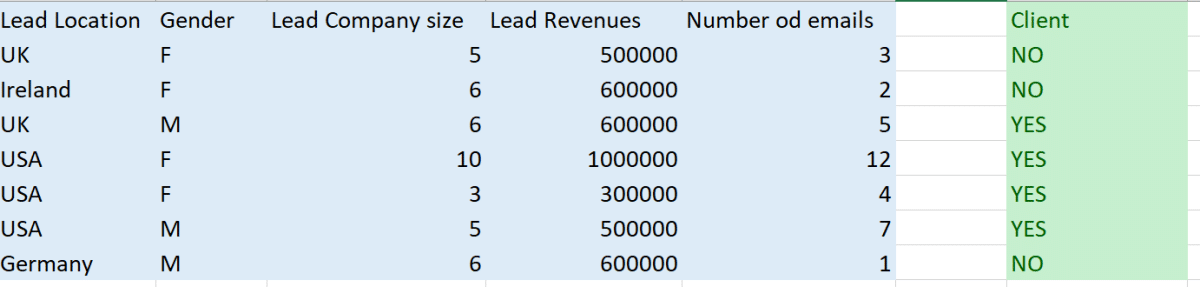
Labeled datasets use human judgment to classify a piece of unlabeled data. The labels depend on the problem that needs to be solved. For example, you may want to predict customer behavior, and see if they will buy from you again. When you label data, you give your machine learning algorithm an identifier to work with.
Unlabelled data
Unlabelled datasets are samples of natural or human-made items. Unlabelled data might include images, audio and video recordings, articles, social media posts, medical scans, audio recordings, or news articles. These items have no labels or explanations. They are raw data.
Machine learning models and how they use data
ML models can help you resolve problems such as forecasting market prices. It all depends on the problem you need to solve.. ML modeling uses three main groups to do this:
- Supervised Learning.
- Unsupervised Learning.
- Reinforcement Learning.
Supervised learning
Supervised learning uses labeled datasets in algorithms to classify data and predict outcomes. Supervised learning is used in most software applications. These include text processes and image recognition. Supervised learning helps companies solve real-world problems. Supervised learning helps you classify top leads, customer status, and detects spam email.
The labeled datasets used in supervised learning add labels to the observations. These labels come from observations from specialists or experts in the field. These labeled datasets then go through classification and regression algorithms. Thereafter, they make a predictive analysis.
Classification Algorithm
Classification algorithm in supervised learning is used when a class label is predicted based on the given data. Classification predicts a state, such as answering a positive or negative outcome. Some models use larger sets of states, and these could include the following real-world situations:
- Classifying negative or positive reviews of a business, movie, or service, based on the words used or the ratings given.
- Classifying whether sales leads will convert based on historical behavior.
- Classifying whether a customer will cancel a service based on historical behavior.
- Predicting if a user will click on a link based on past website interaction and user demographics.
- Classifying whether social media users will befriend or interact with other users. This would be based on a list of mutual friends, demographics, interests, and user history.
Regression Modeling
Another method used in supervised machine learning is regression analysis. Regression predicts numbers, like price, revenue, costs, and similar concepts. Regression modeling can predict numbers based on the features of the data. Regression can be used in the following real-world situations to determine a more accurate prediction on:
- The price of houses in the housing market, based on location, dimension of the house, number of rooms and facilities.
- The amount someone will spend on a product, based on their purchase behavior and transaction history.
- The expected lifespan of a patient, using data based on symptoms, health history, and medical records.
Unsupervised Learning
Unsupervised learning uses unlabeled data and more difficult algorithms. As it is unlabelled data, and very little information has been collected, the outcomes or predictions are also unlabeled. Unlabelled data used in unsupervised learning could still reveal useful information. For example, the model can still inform users whether the data is similar or not, and could group the data based on similarity alone.
Unsupervised machine learning is the branch that deals with unlabeled datasets. There are two types of unsupervised learning:
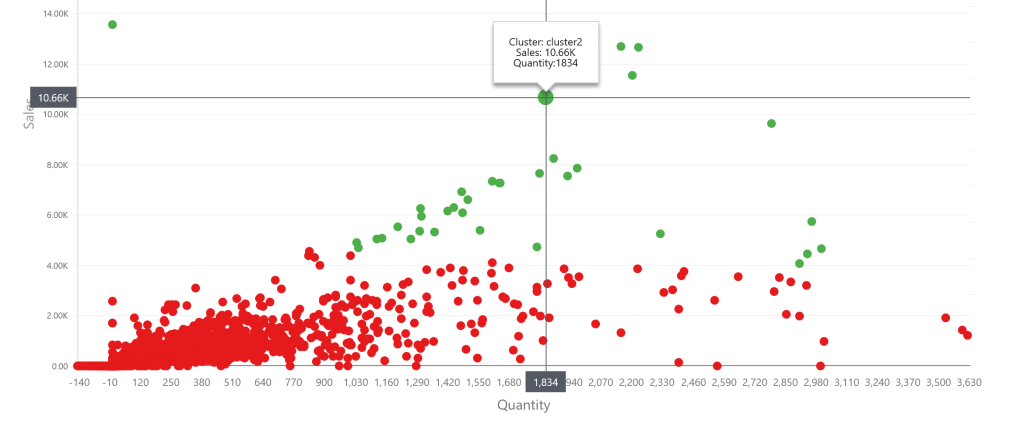
- Clustering: Clustering groups data based on similarity. If the data has a set of images of random animals, it might group the data based on the number of animals, or the animals’ color. Clustering can be used by businesses to segment customers, split types of items, segment products, or similar.
- Dimensionality Reduction: Dimensionality reduction simplifies the data. Dimensionality reduction describes it using very few features. Dimensionality reduction focuses on the most important features of the data. Dimensionality reduction removes the noise that overcomplicates a dataset. The fewer dimensions used for the data, the fewer parameters there are in the model. Dimensionality reduction gives your machine learning model more room to fit in new data. This could then be used for visualization and as a training model.
- Reinforcement Learning: Reinforcement learning uses no data. Reinforcement learning uses an environment and an agent to achieve specific goals. The environment then provides the possible outcomes. This then guides the agent in future situations to complete its goal. Reinforcement learning focuses on finding a balance between exploration and the agent’s current knowledge.

One real-world example of reinforcement learning is predicting stock prices. Using reinforcement learning in this area allows an agent to buy, sell, or hold a stock. They can also evaluate market conditions to take the right course of action at the most favorable time.
Conclusion
There are many ways artificial intelligence can help your business achieve its goals. Collecting data is important, but it’s not enough. Businesses and companies must be able to undertake data annotation and data labeling to inform their decision making. Predictive analytics can help your business improve performance or launch new products. You don’t need to be a data scientist to tackle machine learning. With the right rools and the right data, you can use machine learning to further your objectives. The right data for machine learning projects helps you use predictive analytics. You can make better strategic decisions using predictive analytics.


