
Machine learning is changing how we solve problems. Machine learning is a subset of artificial intelligence (AI) that focuses on data-driven predictions. Machine learning algorithms learn from data to make decisions without explicit programming.
What is Machine Learning?
Machine learning uses statistical techniques to give computers the ability to learn. Machine learning enables systems to improve their performance on a task over time. This field is closely related to data mining and predictive analytics.
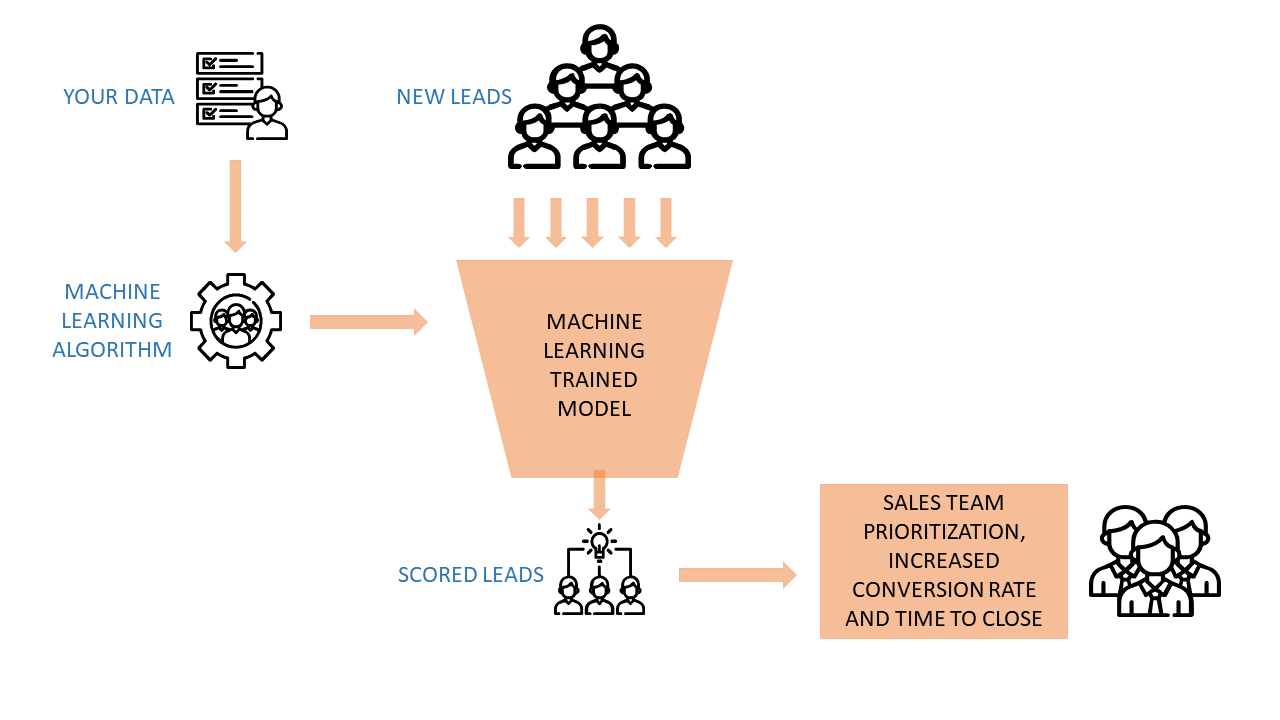
A Beginner’s Guide to Machine Learning: Predictive Lead Scoring
Types of Machine Learning
There are three main types of machine learning:
- Supervised Learning: In supervised learning, the algorithm learns from labeled data. Supervised learning is commonly used for classification and regression tasks.
- Unsupervised Learning: With unsupervised learning, the algorithm finds patterns in unlabeled data. Unsupervised learning is useful for clustering and dimensionality reduction.
- Reinforcement Learning: In reinforcement learning, the algorithm learns through trial and error. Reinforcement learning is often applied in robotics and game playing.
Key Concepts in Machine Learning
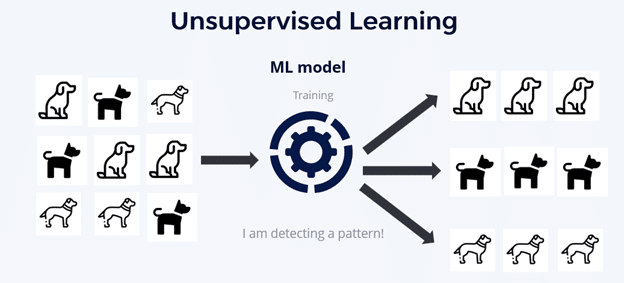
Here are some key concepts around machine learning you need to understand:
- Data: Data is the foundation of machine learning. Big data has fueled advancements in this field. Machine learning algorithms need large amounts of data to learn effectively.
- Features: Features are the individual measurable properties of the data. Good feature selection is crucial for model performance. Feature engineering involves creating new features from existing ones.
- Machine Learning Models: Models are the core of machine learning. Machine learning models represent the learned patterns. Common models include decision trees, support vector machines, and neural networks.
- Training: Training is the process of teaching a machine learning model using data. Model training involves adjusting model parameters to minimize errors. The goal is to create a model that generalizes well to new data.
- Deep Learning and Neural Networks: Deep learning is a subset of machine learning based on artificial neural networks. Neural networks are inspired by the human brain’s structure. They consist of interconnected nodes organized in layers. Deep learning has achieved remarkable results in various fields. It’s particularly effective for image and speech recognition tasks. Deep learning models often require more data and computing power.
Regression
Regression in machine learning predicts continuous outputs based on input features. Regression is used in finance, healthcare, and marketing to understand relationships between variables. In finance, analysts use regression to forecast stock prices using historical data and market trends. Healthcare professionals apply regression to predict patient outcomes and identify disease risk factors. Analyzing large datasets, regression helps make informed decisions in various fields.
Linear Regression
Linear regression finds the best line to show how input and output variables relate. A linear regression model estimates line coefficients to predict new data points. Linear regression works well when input and output have a straight-line relationship. In marketing, it can predict sales from ad spending and customer information. This helps businesses improve their strategies and use resources better. Linear regression isn’t good for complex, non-straight relationships. When data doesn’t follow a straight line, other regression methods are needed.
Nonlinear Regression
Nonlinear regression methods help when relationships between variables aren’t straight lines. Two common types are polynomial regression and support vector regression (SVR). Polynomial regression adds higher-order terms to capture curves in data. Polynomial regression fits complex shapes, making it useful in fields like physics. SVR uses support vector machines to model nonlinear relationships. It transforms data to higher dimensions, capturing complex patterns. This works well for image recognition and language processing.
These methods offer more flexibility than linear regression. They can model complex relationships more accurately. This improves predictions and overall performance in many fields.
Classification
Classification is another important area in machine learning, where the goal is to assign input samples to predefined categories or classes. Classification algorithms are widely used in areas such as image recognition, spam filtering, and fraud detection.
Applications of Machine Learning
Machine learning has numerous real-world applications, which demonstrate the versatility and power of machine learning techniques. Machine learning applications include image recognition, speech recognition, natural language processing (NLP), recommendation systems, fraud detection, autonomous vehicles, medical diagnosis, and financial forecasting.
Classification algorithms are widely used in areas such as image recognition, spam filtering, and fraud detection. One practical application of classification is in image recognition. With the increasing amount of digital images available, the need for automated image classification has become crucial. Classification algorithms can be trained to recognize specific objects or patterns within images, enabling tasks such as facial recognition, object detection, and even medical image analysis.
Spam filtering is another common application of classification. Classification algorithms can be trained on large datasets of known spam and non-spam emails, learning to distinguish between the two based on various features like keywords, sender information, and email structure.
Fraud detection is another area where classification algorithms play a key role. Financial institutions, for example, can use classification algorithms to identify suspicious transactions and flag them for further investigation. Through analyzing patterns in historical data, these algorithms can learn to identify potentially fraudulent activities, helping to prevent financial losses and protect customers.
Tools for Machine Learning
Several tools can help you get started with machine learning:
- Python: A popular programming language for data science and ML.
- R: Another language commonly used for statistical computing and graphics.
- Scikit-learn: A Python library for machine learning.
- TensorFlow: An open-source library for machine learning and deep learning.
- Jupyter Notebooks: An interactive environment for data analysis and ML.
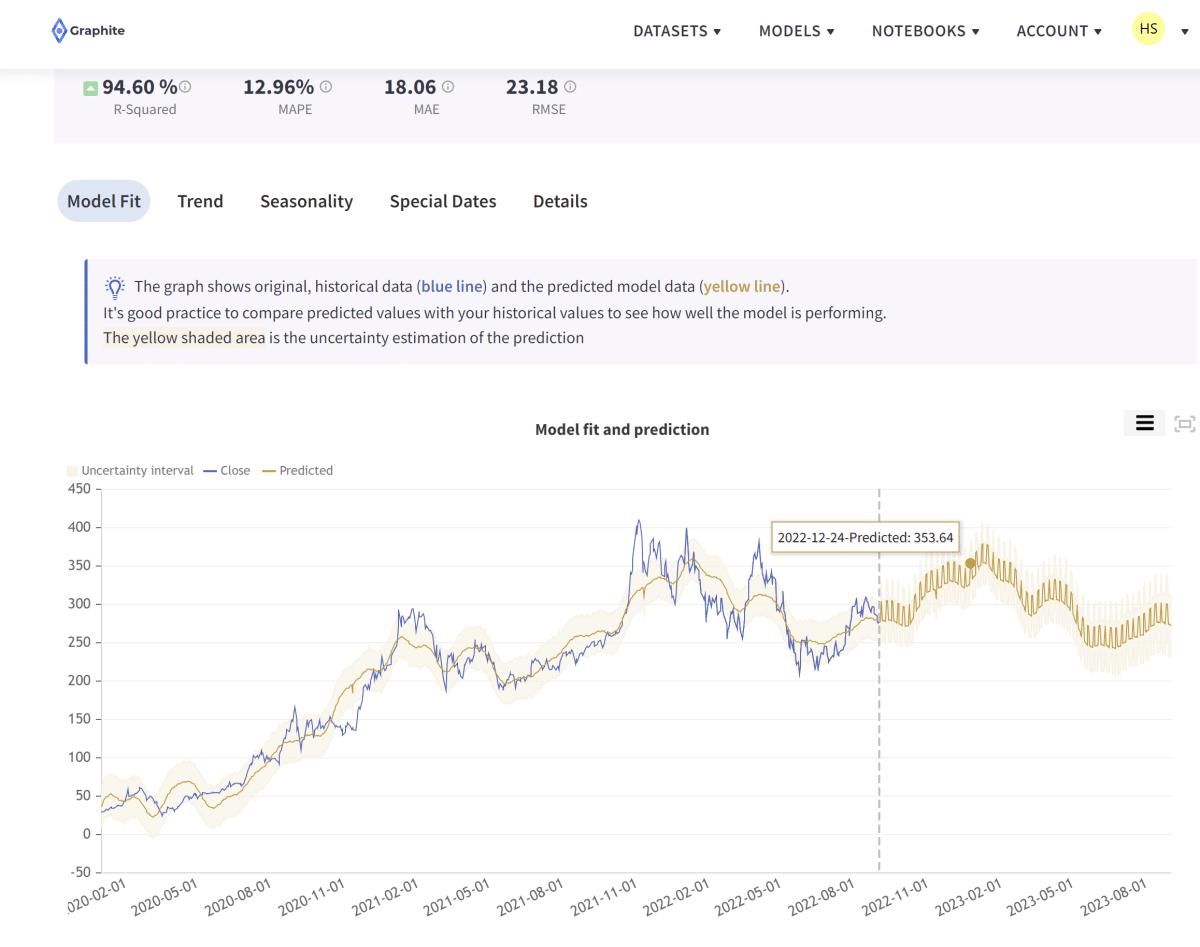
- Graphite Note: With its intuitive interface and powerful capabilities, Graphite Note can help you explore the potential of machine learning without the need for coding.
Challenges in Machine Learning
Machine learning faces several significant challenges that impact its effectiveness and application. Poor data quality can result in inaccurate models, undermining the reliability of predictions and decisions. Overfitting is another common issue, where models excel with training data but struggle with new, unseen information. Interpretability poses a challenge, particularly with complex models like deep learning networks, making it difficult to understand their decision-making processes. Lastly, machine learning raises important ethical concerns, including questions about privacy and potential bias in algorithms and outcomes.
The Future of Machine Learning
The future of machine learning looks promising. Advancements in AI and big data will drive further innovation. Machine learning will likely become more accessible and integrated into various industries.


