
You need relevant datasets for machine learning models. To build a machine learning model, you need data. Not just any old data will do. The data you use for training your models must be representative of the problem you are trying to solve. What kind of dataset for machine learning is appropriate for machine learning? Machine learning algorithms have revolutionized numerous fields. Their power hinges on a crucial element: machine learning datasets. These datasets provide the raw data that algorithms learn from, shaping the resulting machine learning models, and their results.
As we discuss datasets for machine learning projects, we will look at:
- What datasets for machine learning are.
- What datasets for machine learning look like.
- What public datasets are available for you to get started.
- The types of problems each dataset is best suited for solving.
What Is a Dataset?
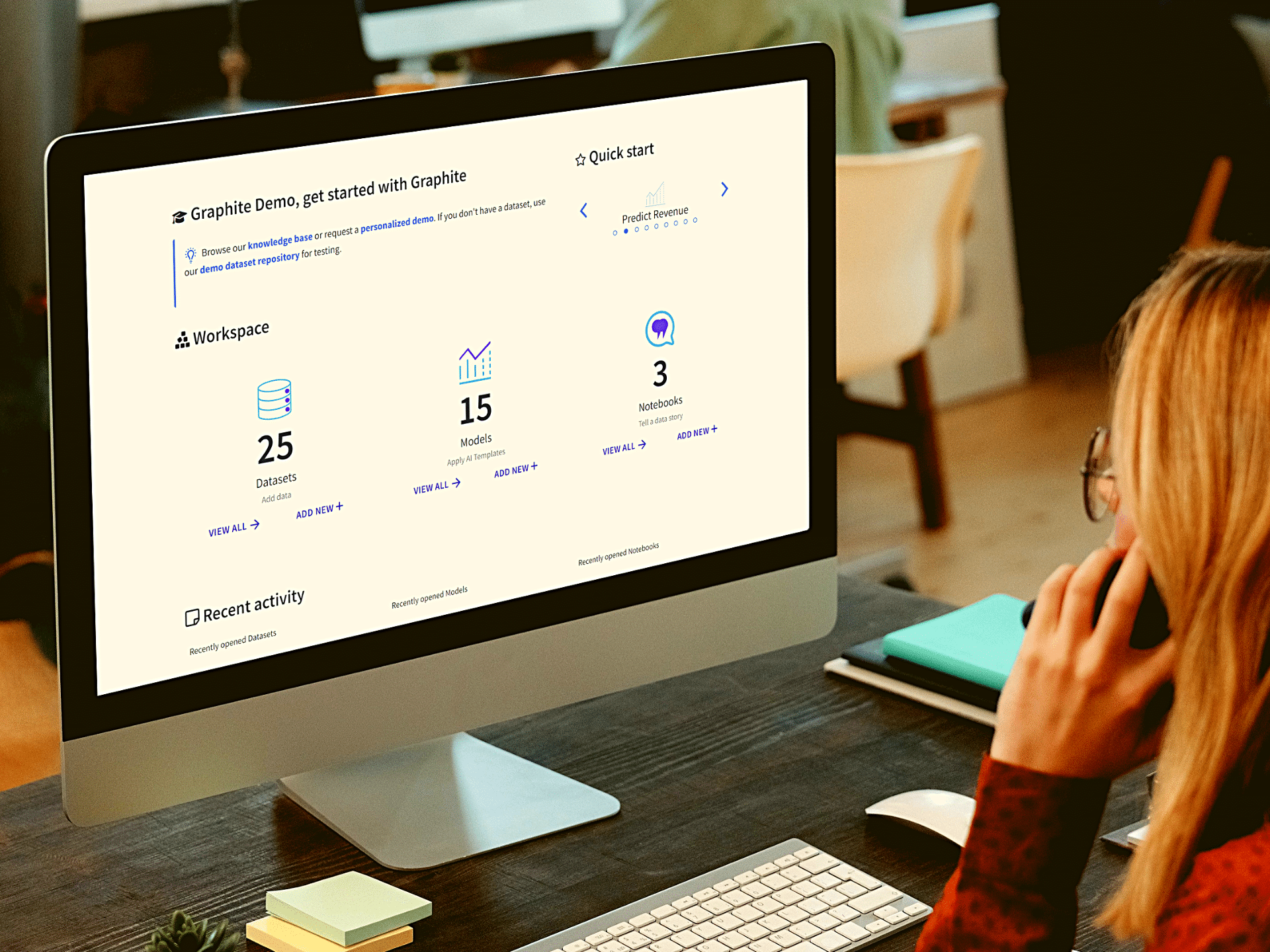
A dataset is a collection of data that machine learning models can train on. These datasets provide enough information so that the model can learn how to generalize from a particular type of context. The machine learning algorithm can then make predictions about new data in other situations where they might be applicable. An example of this is customer demands, sales patterns, or stock levels.
With tons of historical data at hand, you can get better insight into what could happen next in your business. This helps you make more informed decisions that will improve your business outcomes.
What Does a Dataset for Machine Learning Look Like?
Your business can use datasets to track customer behavior, understand trends, and make predictions. Datasets can be small, containing only a few dozen data points, or they can be large, containing millions or even billions of relevant data points for analysis. No matter their size, datasets contain valuable information that help you make intelligent decisions for your business. Thanks to technological advances, it is now easier than ever to collect and analyze datasets. As a result, datasets play an increasingly important role in various industries all over the world.

Lead Scoring Dataset for Machine Learning
A lead scoring dataset is a collection of data that is used to train a machine learning algorithm. A lead scoring dataset is used to train the model to predict whether or not a lead will convert into a paying customer. The dataset should contain:
- Demographic data.
- Customer behavior/engagement data.
- Purchase history.
- Other relevant information.
The machine learning algorithm must learn which leads are most likely to convert and why. This way, sales representatives can focus their efforts on the leads with the highest chances of conversion.
After the model is trained, you can ask the machine for predictions on new leads. Your sales representatives can then use this information to prioritize their time and resources. By using a lead scoring dataset, you can efficiently boost conversion rates.
Churn Prediction Dataset for Machine Learning
A churn prediction dataset is a valuable tool for machine learning. It is a labeled dataset that includes information on:
- Customers who have subscribed to a service.
- Their tenure.
- Their size.
- Their industry.
- Their location.
- Other relevant information.
This dataset can be used to build a model that predicts whether or not a customer is likely to cancel their subscription. This is essential data for businesses to track. This way, you can develop effective strategies to prevent customer churn and ensure customer success.
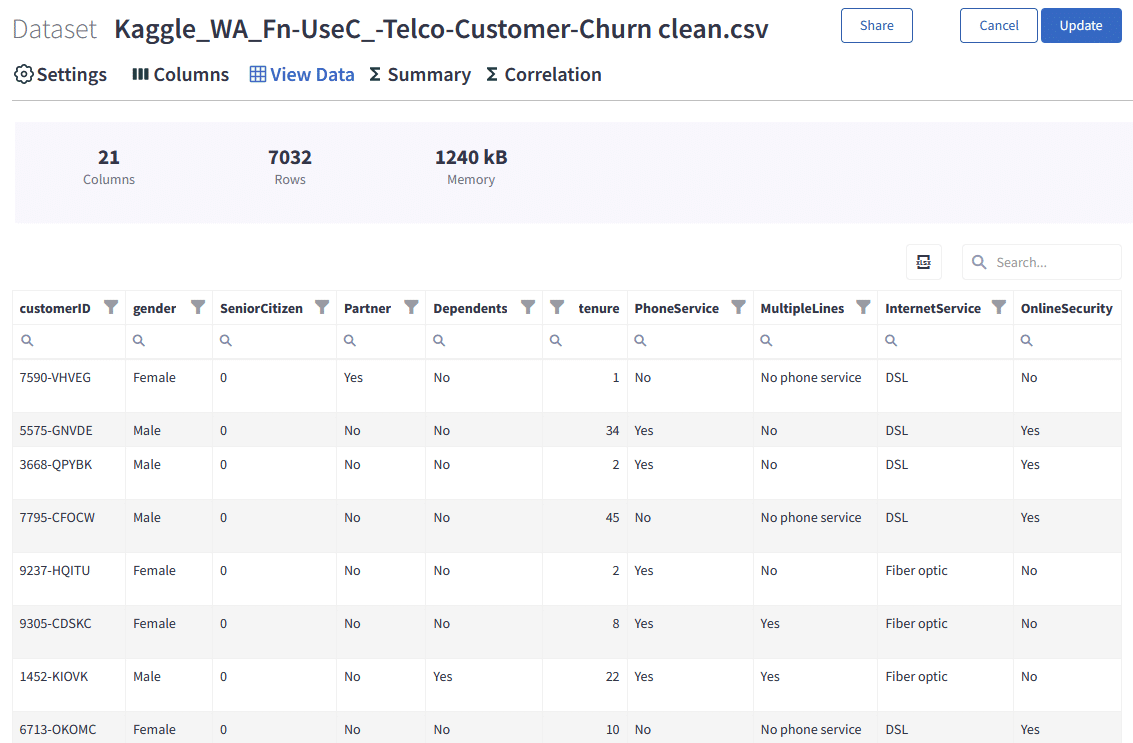
How to Choose the Right Dataset for machine learning
Choosing the appropriate machine learning datasets is important. This ensures you build robust, effective machine learning models. Here are some tips on how to choose the right dataset for machine learning:
- Understand the machine learning algorithm: Different machine learning algorithms require specific data formats and features. For example, image classification algorithms require image datasets. Natural language processing algorithms need text-based datasets.
- Split your training datasets and testing datasets: Datasets are typically divided into training and testing sets. A training dataset is used to fit the machine learning model. A testing dataset will evaluate your machine learning model’s performance.
- Check data quality: Datasets often contain errors, missing values, or inconsistencies. Where you find errors or gaps, Graphite Note can help to fill in the gaps.
- Undertake data cleaning: Data cleaning techniques ensure the quality and integrity of the data you use for training your machine learning model.
- Choose a diverse dataset of the right size: The size and diversity of a dataset significantly affect the performance of a machine learning model. Large and diverse datasets usually lead to better generalization and reduced bias.
- Consider the ethical ramifications: Make sure your datasets are ethically sourced and free from biases that could lead to discriminatory outcomes.
Examples of Publicly Available Datasets for Machine Learning
Publicly available datasets for machine learning are labeled data points that can be used to train and test machine learning models. These datasets contain:
- Numeric data.
- Categorical data.
- Textual data.
All this data is labeled with the correct classification so that your machine learning algorithm can learn from them.
Public datasets for machine learning
Open datasets, that are readily available for public use, are a cornerstone of machine learning progress. An open dataset can be used to train your machine learning model for your data science project. Platforms like Google Dataset Search and the AWS Open Data Registry make it easier to discover and use open datasets.
Here are a few examples of public datasets for machine learning to get you started:
- Palmer Penguin: The Palmer Penguin dataset is an excellent resource for those looking to practice their classification and clustering skills. The dataset comprises two parts, each containing data on 344 penguins. This is a great choice for practicing a wide range of algorithms. The Palmer Station Antarctica LTER has shared extensive documentation on this dataset. Whether you’re looking to use traditional methods like decision trees or random forests, or try something more innovative like support vector machines, the Palmer Penguin dataset is an excellent starting point.
- Fashion MNIST: Fashion MNIST is a fantastic dataset for practicing image classification, with a training dataset of 60,000 images and a testing set of 10,000 clothes images. All images are size-normalized (28×28 pixels) and centered.
- BBC News: The BBC News Datasets contains 2225 high-quality articles from a reputable source. Each article is labeled with one of five categories: tech, business, politics, entertainment, or sport. The labels are evenly distributed, so no category is significantly over-or under-represented. These datasets for machine learning can be used for text classification and other NLP tasks like sentiment analysis.
- Spam SMS Classifier: The Spam SMS Classifier dataset is excellent for solving spam detection and text classification problems. The dataset is heavily used in literature, and it is fantastic for beginners. The dataset consists of a collection of SMS messages that have been classified as spam or non-spam. The dataset is divided into two sets: a training set (5,000 messages), which is used to train the classifier, and a test set (1,000 messages), which is used to evaluate the performance of the classifier. The goal of the classifier is to learn from the training set and correctly classify new SMS messages as either spam or non-spam. The classifier’s performance is measured by its accuracy on the test set.
- The Kaggle dataset: The Kaggle dataset is a popular platform for data science enthusiasts. This dataset offers you a vast collection of machine learning datasets categorized for various applications.
- The UCI machine learning repository: The UCI machine learning repository contains well-known datasets that are often used in research papers.
Other datasets you can use for machine learning
When you’re looking for machine learning datasets, it’s important to consider the type of problem you’re looking to solve. For specific tasks, datasets are further categorized. Image datasets, or computer vision datasets, can be used to develop computer vision models for tasks like image classification, object detection, and facial recognition. Economics datasets enable you to analyze market trends and financial data. Natural language processing datasets train models for sentiment analysis and text mining. Government datasets can give you valuable insights into public services and infrastructure. Diverse datasets, like the Amazon product datasets, can be used for specific research needs. High-quality datasets are essential for building robust machine learning models. Microsoft Research Open Data and other research data repositories provide meticulously curated datasets suitable for academic projects.
Datasets for Machine Learning: The Takeaway
You need high-quality datasets to train a machine learning algorithm and make it do what you want. You can collect datasets from different sources, such as online surveys or social media platforms. The more accurate and complete the dataset, the better the machine learning algorithm will perform. We hope this article has helped you understand how to select a good dataset for your machine learning project and given you some ideas on where to find high-quality data.


