![The Machine Learning Supervised Method and Applications [2024]](https://graphite-note.com/wp-content/uploads/2022/03/feature-The-Machine-Learning-Supervised-Method-and-Applications-2024-1024x576.png)
What is Machine Learning Supervised?
One of the most popular branches of machine learning is supervised machine learning. Machine learning supervised is one of the most accurate machine learning methods. Supervised machine learning techniques to predict concise data needed in various industries.
What Is the machine learning supervised method?
Supervised machine learning is a predictive analysis technique. Supervised machine learning makes predictions based on data inputs or features. Supervised machine learning techniques are where machines are trained to predict data outputs. Supervised machine learning algorithms use well labeled training data. The data input for supervised machine learning isa set of examples classified into one of two categories: the positive and the negative.

What’s the difference between supervised machine learning and unsupervised machine learning?
Supervised machine learning requires labeled data. Unsupervised machine learning deals with unlabelled data. This is where the data points lack predefined labels or categories. In unsupervised machine learning, the machine learning model is left to its own devices. The unsupervised machine learning and unsupervised learning models must discover hidden patterns and structures within the data on its own. Unsupervised learning algorithms are often used for tasks like clustering and dimensionality reduction. While an unsupervised learning technique doesn’t use labeled data, it can be difficult to interpret the results. This also means it’s difficult to assess if the model is on the right track. Unsupervised learning algorithms have a variety of use cases, but we’ll discuss those another time.
What is the goal of supervised machine learning?
In supervised machine learning, the goal of the analysis is to predict the value of a label for new data, or unseen data. New data is usually unlabeled data. Supervised machine learning processes labeled data and produces statistical estimations for future outcomes. Supervised machine learning techniques can be useful in many applications.
How do machines learn with a supervised learning algorithm?
A supervised algorithm breaks the data into two parts:
- The training dataset: The training dataset is used to make predictions based on past observations of the data. The training set is a key part of a supervised machine learning model. The entire training dataset is processed to find features through a mathematical formula, or other methods. Once the training set has processed the input data, these features are found and assigned numeric values (also called labels). Thereafter, using the supervised learning technique, they’re combined to form a majority opinion among them. This creates an aggregate prediction for future outcomes. This is then used to configure the correct answer, or correct outputs, for the machine learning model.
The testing set: The testing set is the real test to see how good the machine learning algorithm is at making predictions. If a model can accurately predict a future outcome with the test dataset, it’s considered to have the correct outputs and is ready for production.
Supervised machine learning applications
While many different applications use supervised machine learning, these are some of the more common use cases. As we outline these use cases, we also include tips on input data, data points, and supervised learning work. Remember: you don’t need to be a data scientist to use machine learning. No-code machine learning tools can help.
Retail
Supervised machine learning algorithms are used in retail to predict customers’ purchasing behavior. Supervised machine learning can predict future sales based on previous purchases. It can use relevant data points like: time of day, store type, income level, or other data points. A supervised machine learning algorithm can help with inventory levels and staffing decisions. Supervised machine learning has become an invaluable tool in the retail industry.
Supervised machine learning could save retailers over $400 billion soon. These technologies enable retailers to gain a deeper understanding of their customers. Deep learning algorithms can also help retailers understand their customers’ spending habits. This enables retailers to craft personalized marketing campaigns. Supervised machine learning can also help retailers improve stock management, and reduce waste. Supervised machine learning is also applicable for data security.
Supervised machine learning tools can detect suspicious activities and prevent breaches. Supervised learning models have revolutionized the retail landscape. Supervised machine learning helps retailers remain competitive.
Finance
Finance also uses a supervised learning algorithm for predictions. These include predicting stock market volatility based on past trends performed. Financial institutions also use supervised machine learning for fraud detection and anti-money laundering. Supervised machine learning is becoming popular in finance as it can accurately predict outcomes.
Supervised machine learning can help to forecast stock prices. Supervised machine learning algorithms can identify fraud, and guide investment choices. JPMorgan Chase, Goldman Sachs, and Morgan Stanley have invested in supervised machine learning. Nearly 62% of US financial services companies are using some form of supervised machine learning. One specific application of supervised machine learning in finance is credit scoring. Using algorithms, lenders can better assess the creditworthiness of potential borrowers.
They can also more accurately predict if they will default on a loan or make late payments. An estimated 85% of lending decisions are now based on AI-driven models and techniques. These models have enabled institutions to reduce fraudulent activity.
Health
A supervised machine learning algorithm can also help to predict health outcomes. More recent applications also include cancer cell detection. where machine learning algorithms are used to sort cancerous cells from non-cancerous ones. The use of supervised machine learning in the health sector is growing. Healthcare organizations can leverage machine learning technologies to identify important trends and correlations. This helps to improve patient care. Supervised machine learning provides valuable insights into a range of medical applications.
IBM Watson Health found that using imaging supported by artificial intelligence can reduce false negatives by 87%, compared to human interpretation alone. Clinical trials have also found that AI-assisted diagnosis speeds up process and diagnosis. This leads to earlier diagnoses and better treatment outcomes. Stanford University showed that a deep learning algorithm could predict heart failure hospitalizations with 91% accuracy. That level of correct output has more than 5% greater accuracy than traditional models.
Spam detection
Supervised machine learning is used in spam detection. Spam detection filters out unauthorized senders hiding behind fake addresses. Spam filtering and spam detection is undertaken by monitoring targets. These are the senders’ addresses, and they are monitored for changes, over time. Supervised machine learning is a powerful tool for spam detection and prevention. Organizations can build supervised machine models that sort through incoming emails. All emails are then classified as spam or not. This keeps users safe from malicious messages.
It also reduces time spent sorting through emails. 58.3% of all emails sent in 2019 were identified. An additional 12.2% were classified as potentially dangerous phishing or malware-laden messages. This type of machine learning model can help to reduce these numbers by detecting and blocking spam or malicious emails before they reach the inbox. Gmail relies on supervised machine learning for its spam filters. Deep learning algorithms are especially effective at identifying legitimate users from malicious ones.
Weather forecasting
Supervised learning algorithms help predict weather changes by using historical data. For example, the past 24 hours of weather data points can be used to determine the weather the next day. Supervised machine learning has become popular in weather forecasting. It can provide more accurate predictions of upcoming weather compared to traditional methods. Meteorologists can consider various factors. These include: temperature, atmospheric pressure, humidity, and wind speed.
By combining this information with other data sets, supervised machine learning can give high accuracy detailed forecasts. The University of Miami found that using supervised machine learning in hurricane prediction increased accuracy by up to 90%. The International Journal of Forecasting showed that using supervised machine learning improved accuracy in the output value by 10%.
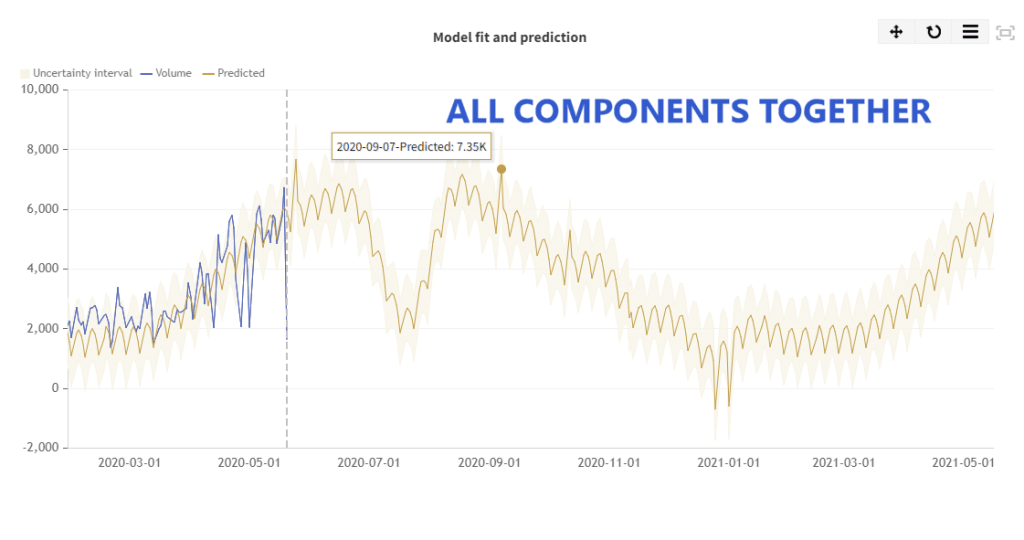
Image classification
Supervised machine learning is also used in image classification. Image classification compares images to compare similarities between them. Similar images are placed in the same category. New images are categorized according to the rules set for this model. This is useful for separating similar images that may contain more details that distinguish them from each other. It is effective even when the images may have been taken at the same times and from the same angles. Image classification is one of the most popular applications of supervised machine learning. By leveraging labeled training data, machines can accurately identify and classify images.
The average error rates for image recognition have decreased from 28% in 2012 to less than 5% today. Healthcare professionals can use machine learning to accurately identify tumors or make diagnoses. Facial recognition technology is also used for security purposes. This enables machines to determine if someone is a wanted criminal or an unauthorized visitor. Self-driving cars use image classification algorithms to avoid obstacles on roads and highways.
Facial recognition
Facial recognition technology uses supervised machine learning to identify people in photos or videos based on their facial features. The use of supervised machine learning models in face recognition has revolutionized the way we validate identity. This adds an extra layer of security to our everyday lives. Supervised machine learning algorithms now power over 95% of face recognition systems.
Compared with traditional matching techniques, these algorithms have significantly increased accuracy in output values and improved scalability. The cost associated with obtaining the necessary training data has also dropped.
Therapeutic drug interactions
Supervised learning algorithms can also be used to predict the side effects of new medications. Supervised learning techniques can also predict how new medications interact with other medications. Supervised learning algorithms can also determine when an overdose has occurred. A model assesses the chemical structure of the drug and potential receptor interactions. With predictive algorithms, physicians and pharmacists can identify possible drug interactions.
This enhances patient safety. In the United States alone, over 3 billion prescriptions are filled each year. By deploying this tool in clinical practice, it is estimated that the rate of adverse events related to medication interactions can be reduced by up to 30%.
Predictive lead scoring
Sales and marketing teams find it challenging to predict their conversion rates, especially when they have multiple lead pipelines. Generating leads is the lifeblood of your business. Your ability to prioritize and follow up on the right ones can significantly affect your bottom line. Gathering data on lead scoring or categorizing lead attributes and activities can be a tremendously tedious task when done manually. A supervised learning model can help you achieve and exceed your objectives. Machine learning models can help you get closer to the correct answer when it comes to predictive lead scoring.

Predict customer churn
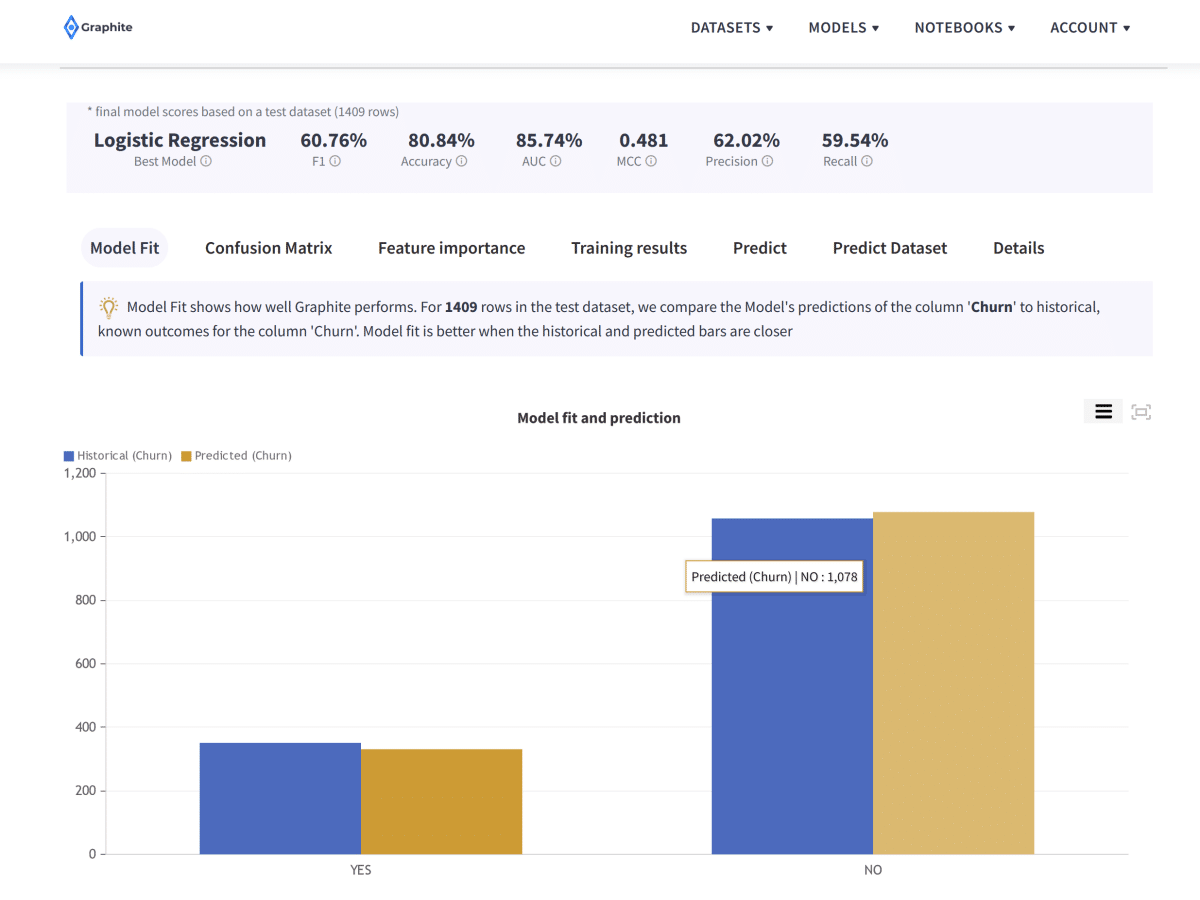
The one challenge businesses always face is customer churn. A churn is when customers stop buying a product or opt-out of service. Often, this entails the need to find new leads and pipelines so you can still meet revenue targets. The more ideal solution, however, is to map out reasons for customer churn to prevent customers from turning to a competitor. Understanding customer churn goes together with customer retention analysis. Knowing why customers are leaving helps you understand customer sentiment and behavior. Supervised machine learning can help to improve your customer retention rates. Supervised learning also helps you understand the weaknesses of your product and strategy. Supervised machine learning models can help your business predict customer churn.
Supervised machine learning is used in various industries and professions. Supervised machine learning helps you make informed decisions with greater accuracy. You don’t need to be a data scientist to get started.