 Skip to content
Skip to content 
K-Fold cross validation is a pivotal technique in the realm of machine learning, embodying an intricate balance of scientific method and empirical testing. By understanding K-Fold, data scientists and machine learning engineers can enhance their models’ reliability. This comprehensive guide explores the nuances and applications of K-Fold cross validation, providing clarity on its importance, mechanisms, and best practices. Let’s embark on this enlightening journey.
Introduction to K-Fold Cross Validation
Cross validation is a fundamental practice in model evaluation. It ensures that the generalization of a model is tested rigorously against different subsets of data, which helps to mitigate the risks associated with overfitting. The process involves segmenting the dataset into distinct training and testing sets, allowing for a more robust estimation of model performance.
The Importance of Cross Validation in Machine Learning
In the absence of a sound validation strategy, a model may appear to perform well on the training dataset but fail spectacularly in real-world applications. Cross validation provides a systematic approach to ascertain model robustness by evaluating it on unseen data, thereby enhancing its generalization capability. This is particularly crucial in fields such as healthcare and finance, where the cost of errors can be significant. By employing cross validation, practitioners can ensure that their models are not just memorizing the training data but are learning to make predictions based on underlying patterns that hold true across various datasets.
Defining K-Fold Cross Validation
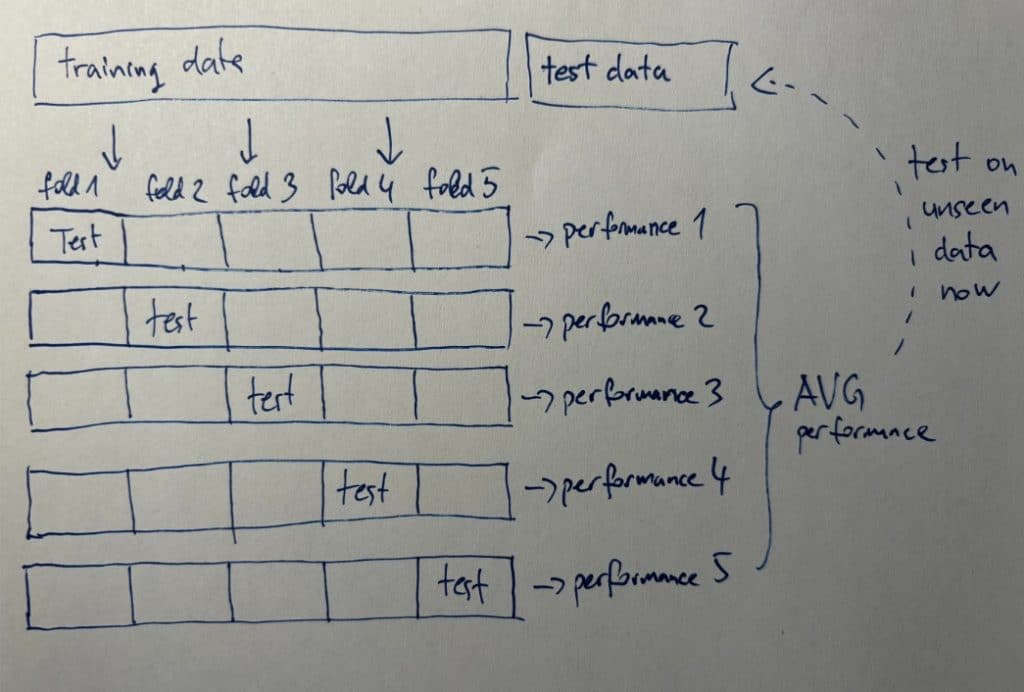
K-Fold cross validation partitions the data into ‘K’ subsets or folds. For each fold, the model is trained on ‘K-1’ folds and validated on the remaining fold. This process is repeated ‘K’ times, with each fold serving as the validation set exactly once. The final performance metric is usually the average of all ‘K’ iterations, providing a well-rounded performance assessment. This method is particularly advantageous because it maximizes both the training and validation data used in the evaluation process, ensuring that every observation is utilized for both training and testing. Furthermore, the choice of ‘K’ can significantly influence the model’s performance; smaller values of ‘K’ can lead to higher variance in the performance estimate, while larger values can increase computational cost. Therefore, selecting an optimal ‘K’ is a critical consideration in the implementation of K-Fold cross validation.
The Mechanics of K-Fold Cross Validation
Understanding the mechanics of K-Fold cross validation is crucial for implementing it effectively. The entire process, while straightforward, involves meticulous attention to the details to ensure that the division and evaluation are performed correctly.
Breaking Down the K-Fold Process
- Data Splitting: Divide the dataset into K equal-sized folds.
- Model Training: For each fold, train the model using K-1 folds.
- Validation: Validate the model using the remaining fold.
- Performance Measurement: Collect the performance metrics from each iteration.
- Averaging Results: Calculate the average performance across all folds to obtain a final metric.
This structured approach ensures that every data point gets to serve as both training and testing data, promoting a holistic evaluation of model performance.
Selecting the ‘K’ in K-Fold Cross Validation
The choice of ‘K’ can significantly influence the results obtained from cross validation. A common practice is to set K to 5 or 10, as these values tend to offer a good balance between training time and model evaluation accuracy. However, the optimal K value often depends on the size of the dataset:
- For smaller datasets, a larger K (like leave-one-out) is useful for maximizing training data use.
- For larger datasets, a smaller K helps in reducing computational expense while still validating effectively.
Experimentation and domain knowledge are key to selecting the appropriate K value.
Benefits of Using K-Fold Cross Validation
The adoption of K-Fold cross validation offers numerous advantages, making it a favored choice among practitioners in machine learning.
Improving Model Performance with K-Fold
By systematically utilizing different subsets of the data for both training and validation, K-Fold cross validation helps in fine-tuning model parameters and exploring various model configurations. This iterative process contributes to the development of a model that is more resilient and adept at predictions across diverse data scenarios.
Mitigating Overfitting and Underfitting
Overfitting and underfitting are two significant challenges in model training. K-Fold cross validation aids in identifying these issues early. It ensures that the model is neither excessively tailored to the training data nor overly simplistic, thus striking a balance that enhances predictive accuracy.
Limitations and Challenges of K-Fold Cross Validation
While K-Fold cross validation is largely effective, it is not without its drawbacks. Recognizing these limitations is crucial for informed model evaluation.
Understanding Bias-Variance Tradeoff
The bias-variance tradeoff is a perpetual concern in machine learning. K-Fold cross validation can sometimes mask these issues; for instance, a model may have low variance but high bias. Continuous evaluation and monitoring of model performance across different K values is essential to navigate these challenges.
Computational Costs and Time Considerations
As K increases, so does the computational cost and the time required for model evaluation. This is especially salient for large datasets or complex models. Balancing the need for thoroughness in validation against resource constraints is a critical aspect of deploying K-Fold cross validation effectively.
Advanced Concepts in K-Fold Cross Validation
Diving deeper into K-Fold practices unveils advanced variants that cater to specific scenarios and enhance validation efficacy.
Stratified K-Fold Cross Validation
Stratified K-Fold cross validation ensures that each fold maintains the original distribution of the target variable. This approach is especially beneficial in classification tasks with imbalanced classes, as it allows for a fairer evaluation of the model’s performance across all classes.
Leave-One-Out Cross Validation
Leave-One-Out Cross Validation (LOOCV) is an extreme case of K-Fold where K is the number of instances in the dataset. Each instance serves as a validation set while the rest are used for training. Though computationally expensive, LOOCV can be exceptionally useful for small datasets, providing a unique perspective on model performance.
In summary, K-Fold cross validation stands as an invaluable technique in the machine learning toolkit. Whether you are refining existing models or exploring new algorithms, incorporating K-Fold analysis into your workflow will undoubtedly bolster your predictive capabilities and enhance your understanding of your model’s true performance.



